Introduction
We can run the Machine Learning Pipeline on Kubernetes locally on Minikube. The KFP can be compile and executed on Vertex AI.
Write Kubeflow Pipeline
We will create a basic pipeline, compile it using KFP SDK.
import os import kfp from kfp import dsl from kfp.v2 import compiler from kfp.v2.dsl import component @component() def hello_world(text: str) -> str: print(text) return text @dsl.pipeline(name='hello-world', description='A simple intro pipeline') def pipeline_hello_world(text: str = 'hi there'): """Pipeline that passes small pipeline parameter string to consumer op.""" consume_task = hello_world( text=text) # Passing pipeline parameter as argument to consumer op if __name__ == "__main__": # execute only if run as a scriptprint("Compiling Pipeline") compiler.Compiler().compile( pipeline_func=pipeline_hello_world, package_path='hello_world_pipeline.json')
We can save the pipeline to hello_world_pipeline.py. We can compile this pipeline to hello_world_pipeline.json .
Compiling Pipeline$python hello_world_pipeline.py
Run Pipeline on Vertex-AI
We will run on Vertex-AI Pipeline.

Click on Create Run

hello_world_pipeline.json path. Choose the default SA from Advanced Options.
Create a GCS bucket and provide the access to Default SA on it. Click Submit.

After few minutes the pipeline will be executed with status succeeded with Green Tick Symbol ✅
The output will also be available on GCS.
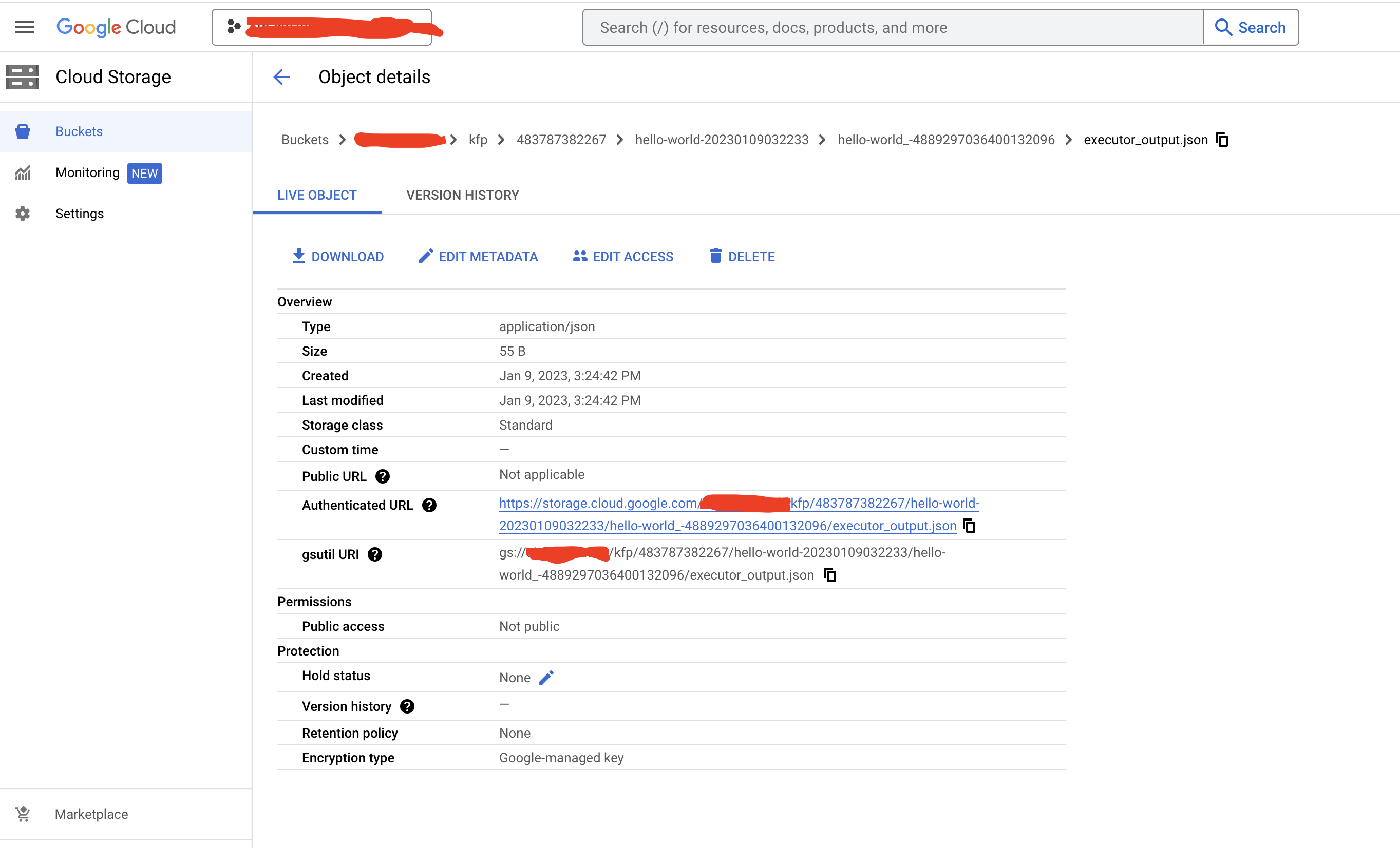
Click or download the file, it will have below output message.

Please post your queries below.
Happy Coding !





















