Apache Hive
Apache Hive is data warehouse software build on top of Hadoop for analyzing distributed HDFS data using HQL (SQL like commands).In this tutorial, we will discuss steps for Hive installation with local embedded datastore.
Prerequisites
- If need to configure hive in cluster, then you must have same version of Hadoop installed on local machine as hadoop version installed on cluster machine.
- If configure hive in pseudo mode, then hadoop must be configured properly. If not, use the article to configure it.
Steps for Hive Installation
In this tutorial, we will discuss Hive installation where meta data reside on local machine using default Derby. This is easy way to start but its limitation is that only one embedded Derby database can access the data file. Therefore, only one hive session open at time can access database or second session will produce error.
Download and extract the binary tarball
Download the binary file from Apache mirror or use wget as shown below.
wget http://mirrors.sonic.net/apache/hive/hive-2.2.0/apache-hive-2.2.0-bin.tar.gz

Extract the tarball
tar -xvf apache-hive-2.2.0-bin.tar.gz
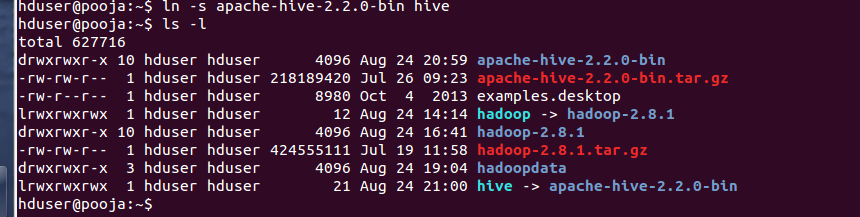
Create symbolic link
ln -s apache-hive-2.2.0-bin hive
Configuration Change
edit ~/.bashrc and add below line.
export HIVE_HOME=<path where hive tar file extracted >
export PATH=$PATH:$HIVE_HOME/bin

Create Hive Derby Schema
As previously mentioned, we are using embedded database derby but in production we install mysql db as metastore and provide the config for mysql in hive-site.xml.
schematool -initSchema -dbType derby

Verify if database schema create.
We created the schema on folder ~/hivedata. Please look for derby database in same folder.

Hadoop Changes
Hive will create store data on HDFS folder /user/hive/warehouse. Therefore, we need to create the folder on HDFS.hduser@pooja:~/hivedata$ hadoop fs -mkdir /user/hive/warehouse/
17/08/24 21:38:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HQL statements
Finally, we will be creating and inserting data using HQL. We are perform data aggregations and filtering and generate insights using simple HQL (with is similar to SQL).
hduser@pooja:~/hivedata$hive
create table demo ( id int, firstname string) row format delimited fields terminated by ','
create table product ( id int, name string, price float);

insert into product values ( 1, "product 1", 10.99);

the table files can be viewed on the HDFS as below

Hope you are able to install Hive without any troubles. If any problems, please write to me.
Happy Coding !!!
Happy Coding !!!
No comments:
Post a Comment